¡Hola!
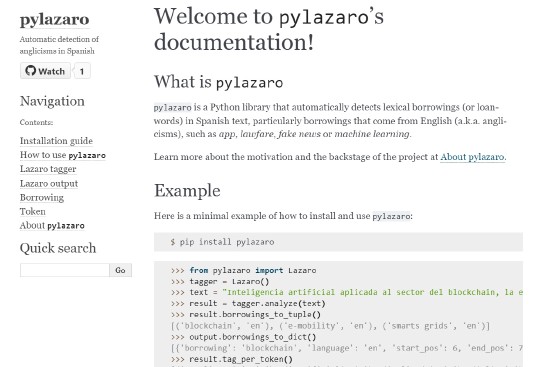
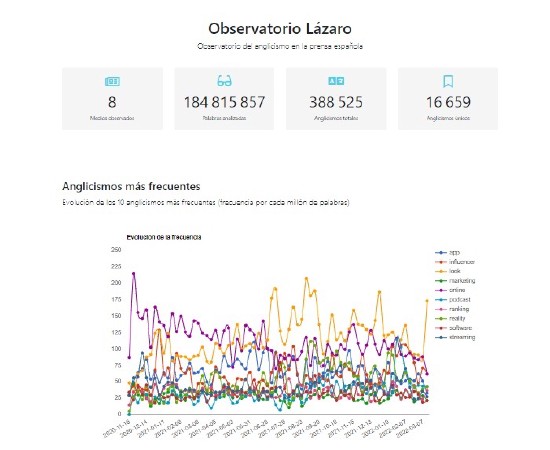
I’m Elena. I’m a computational linguist: I’m interested in Linguistics, technology and the intersection between them. I currently work as a postdoc researcher at the NLP&IR research group at UNED University, where I also did my PhD on lexical borrowing identification under the supervision of Julio Gonzalo and Constantine Lignos. I’m particularly interested in studying how we can use technology to understand language contact and language change. My research has led to the creation of Observatorio Lázaro, an observatory that automatically monitors anglicism usage in the Spanish press.
Prior to that, I spent a decade working on different language technology projects at various organizations, such as the Information Sciences Institute at University of Southern California, Fundéu, Molino de Ideas, McLean Hospital or UNED Digital Humanities Lab.
I am also highly involved in dissemination activities that bridge the gap between Linguistics and the general public: I write a column about language at Spanish newspaper elDiario.es, a column that was awarded with the Miguel Delibes National Journalism Award in 2017. I sometimes write at linguistics magazine Archiletras, where I also serve as editorial board member. In 2016 I wrote the pop linguistics book Anatomía de la Lengua.
Interests
- Computational Linguistics
- Natural Language Processing
- Corpus Linguistics
- Contact Linguistics
Education
-
PhD in Natural Language Processing
UNED
-
MS in Computational Linguistics
Brandeis University
-
BA in Linguistics
Universidad Complutense de Madrid (UCM)