Elena Álvarez Mellado
Assistant professor
Department of Linguistics, UAM
¡Hola!
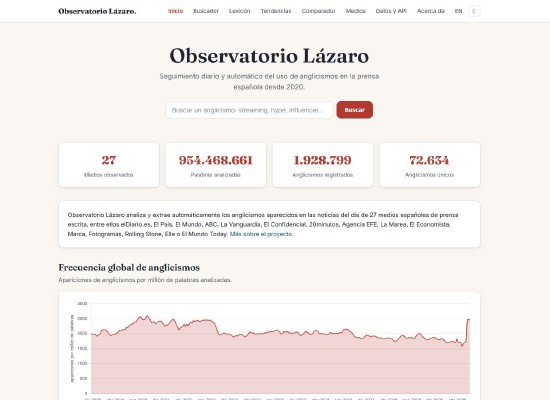
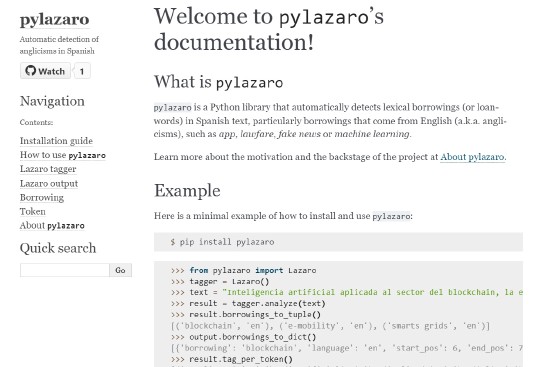
I am Elena. I am an Assistant Professor (profesora ayudante doctora) in the Department of Linguistics at Universidad Autónoma de Madrid, where I specialize in computational linguistics and natural language processing. My research interests lie at the intersection of language and technology, specifically using computational methods to study language contact, lexical borrowing and linguistic change over time. As part of this work, I developed Observatorio Lázaro, a pipeline that monitors the Spanish press daily and has cataloged 2 million instances of anglicisms since 2020.
I hold a MS in Computational Linguistics from Brandeis University and a PhD in NLP from UNED NLP&IR research group, where I focused on lexical borrowing identification under the supervision of Julio Gonzalo and Constantine Lignos. Prior to that, I worked for a decade as a language technology specialist at institutions such as the Information Sciences Institute at the University of Southern California, Fundéu, Molino de Ideas and UNED Digital Humanities Lab.
My research has been recognized and supported by several institutions. I am the recipient of the Adam Kilgarriff Prize (2022), the Generation Google Scholarship for Women in Computer Science (2021), the Premio HDH (2021), and a LaCaixa Scholarship (2018). I am also an honorary member (socia de honor) of ASETRAD.
In addition to my academic research, I am actively involved in public outreach and science communication. I write a regular language column for the Spanish newspaper elDiario.es, for which I received the Miguel Delibes National Journalism Award (Premio Nacional de Periodismo Miguel Delibes) in 2017. I also serve on the editorial board of the linguistics magazine Archiletras, where I am a regular contributor.
Interests
- Computational Linguistics
- Natural Language Processing
- Contact Linguistics
Education
-
PhD in Natural Language Processing
UNED
-
MS in Computational Linguistics
Brandeis University
-
BA in Linguistics
Universidad Complutense de Madrid (UCM)